Upon crossing the finish line of the marathon, the runner was elated to have achieved a
personal record-breaking time (a PR, as any runner loves to call it!), which was tracked via their
newest smartwatch and corresponding mobile application. However, upon attempting to share
this accomplishment with their fellow runners via a social networking platform the following
day, the runner was disappointed as the record had been lost and could not be retrieved ever
again.
There are many probable causes of this problem. Data quality issues resulting into missing or
null values, inadequate exception handling on the application side, communication failures,
absence of failover mechanisms in backend data acquisition component, data format issues
while storing the data resulting into data extraction failure, unplanned system changes; to cite a
few. For such activities to work seamlessly, what we need is robust and meticulous Data
Engineering approach.
Data Engineering is a crucial aspect of any data science or big data project that involves creation
and maintenance of the systems and pipelines that enable the collection, storage, and
processing of large amounts of data. It plays a vital role in data science by enabling
organizations to make use of data in making decisions, performing advanced analytics, and
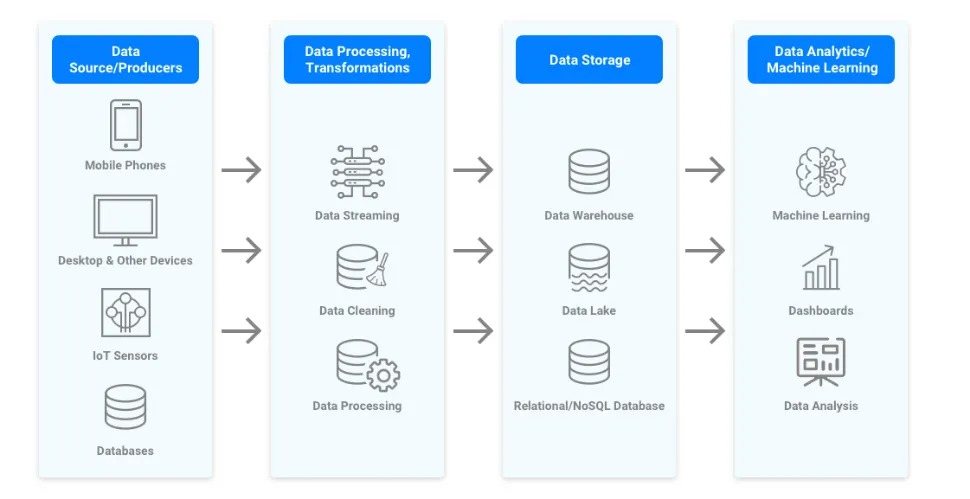
training machine learning models. A typical data pipeline architecture involves various phases
as depicted in the following diagram.
Some of the key aspects of meticulous data engineering are:
1. Heterogenous data
Many modern data engineering techniques involving machine learning and
artificial intelligence often require a mix of structured and unstructured data to make accurate
predictions and do comprehensive analysis. For example, to improve quality of treatment and
overall experience of visiting a doctor, a healthcare platform might need to handle and extract
information from various data types such as, machine data (sensors, wearables etc.), biometric
data (X-rays, scans, fingerprints etc.), data created by human (prescriptions, medical reports
etc.) to name a few. This information comes in various data types, sizes, and features.
Depending on the use case, data goes through three stages storing, transforming, and
analyzing. For storing large amounts of raw, heterogenous data, data lakes such as Amazon S3
or Microsoft Azure Blob are often used. These platforms provide scalable, cost-effective storage
for unstructured data and make it easier to access and process this data later.
Once the raw data has been transformed and processed to meet specific use cases, it can then
be stored in a data warehouse, a relational database management system (RDBMS), or a NoSQL
database. These storage options provide more structured and optimized access to the data for
analysis and decision-making.
2. Reliability and Efficiency
Data pipelines need to be always up and running to acquire, process
and store data in a timely manner.
For instance, in an Industrial Internet of Things (IIoT) system, it's crucial to constantly
process
raw sensor data to determine derived parameters. To guarantee that these calculations are
performed accurately, with no gaps or delays, the system must employ a combination of
concurrent and sequential processing, as well as implement retry mechanisms, anticipate, and
handle out-of-sequence data, manage exceptions, optimize memory and CPU usage, and
caching of results to avoid missing any calculations.
3. Quality
By implementing rigorous data wrangling and validation processes, data engineers help
ensure various traits of data quality such as accuracy, completeness, relevance, and timeliness.
For example, in an IIoT systems, timeseries data may come out of sequence. Consumers of such
data should understand this situation and handle or ignore such out-of-sync data intelligently.
Data validation or wrangling, as it’s called; is very first step before data gets stored or
passed
onto for any analysis.
4. Scalability
Scalability needs to be accounted for right from the design phase. Pipeline should
be able to upscale itself as per the load to remain highly available as well as downscale when
it’s not loaded enough, to save cost.
5. Ease of access
It's important for data engineers to make data easily available because it
enables data scientists, analysts, and other stakeholders to access, search, filter, sort the
data
quickly and efficiently to form decisions, discover new insights, and develop predictive models
without delays. This may also include combining data from disparate data sources, breaking
complex data structures into simpler ones etc. Data is typically made available by REST APIs,
SQL, raw forms such as CSVs or using BI tools.
6. Data security and compliance
It's important to abide by the regulations governing data
transmission and storage in a particular domain. The system must conform to various
standards, depending on the domain and location of data usage, including HIPAA (Health
Insurance Portability and Accountability Act), PCI DSS (Payment Card Industry Data Security
Standard), ISO 27001, and SOC 2, among others.
7. Orchestration and Monitoring
Orchestration of a data pipeline is the process of managing and
coordinating the tasks and processes involved in moving data from various sources to its
destination and it includes scheduling, task management, error handling, and monitoring the
pipeline. There are several tools and frameworks that can be used for orchestration of data
pipeline, such as Apache Airflow, Apache NiFi, AWS Glue to name a few.
With the growth of network connectivity, advancements in cloud computing, and the
proliferation of mobile devices and storage options, the growth of data is exponential. This
increase in data is fueling the importance of data-driven decision making across all industries
and organizational sizes. By having a well-designed and robust data pipeline architecture,
organizations can ensure that their data management processes are efficient, effective, and
aligned with their business goals.